
Introduction
So, you’ve decided to plunge into the wild world of distributed systems. Naturally, you might think, "Why not aim for perfection and nail all three critical factors: Consistency, Availability, and Partition Tolerance?" After all, who wouldn’t want it all?
Enters CAP theorem to rain on that parade, showing us a more practical and realistic approach. In this blog, let me break down how the CAP theorem works, what it means for your systems, and how you can navigate these tricky waters without going nuts!
What is the CAP Theorem?
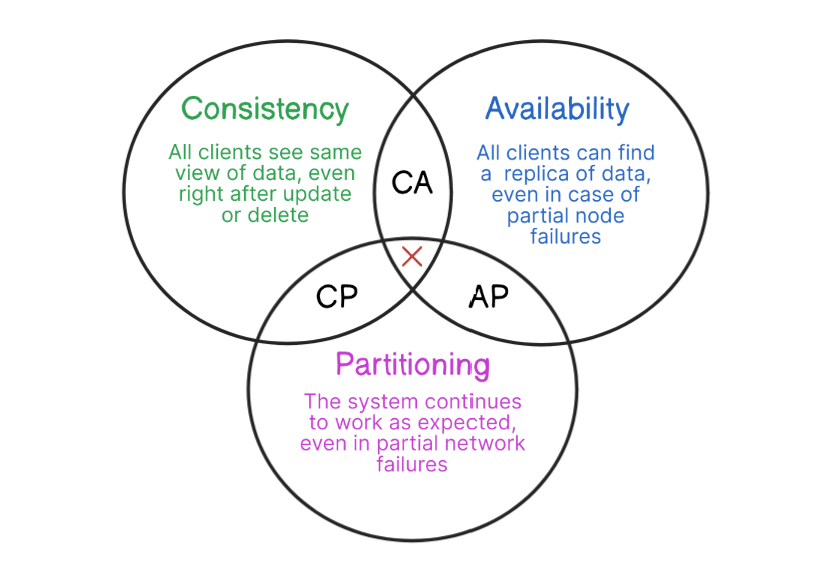
The CAP theorem states that it's impossible for a distributed system to simultaneously guarantee Consistency, Availability, and Partition Tolerance.
Breaking Down the CAP Components:
Let's delve into each of the three components to understand them better.
Consistency
In a distributed system, consistency means that all nodes see the same data at the same time. This ensures that after a write operation is completed, any subsequent read operation will return the updated data, giving every client the same view of the data.
However, achieving strict consistency can lead to increased latency and decreased availability, especially during network partitions or failures. Enforcing consistency often requires complex coordination and can slow down the system, particularly in large-scale networks where data synchronization across nodes can be challenging.
Availability
Availability ensures that every client request receives a response, even if some of the nodes in the system are down. This means that operational nodes will always respond to data requests, though the response may not always reflect the most recent data.
A system that prioritizes availability continues to operate and respond to requests even in the presence of node failures or network partitions. Strategies like data replication and load balancing are commonly used to maintain high availability. While this approach may lead to eventual consistency where different nodes might temporarily have different data versions, it ensures the system remains up and running, providing continuous service to clients.
Partition Tolerance
Network partitions are temporary disruptions that prevent nodes in a system from communicating with each other. These are an inevitable reality in distributed systems, and achieving partition tolerance is crucial for maintaining system reliability under adverse conditions.
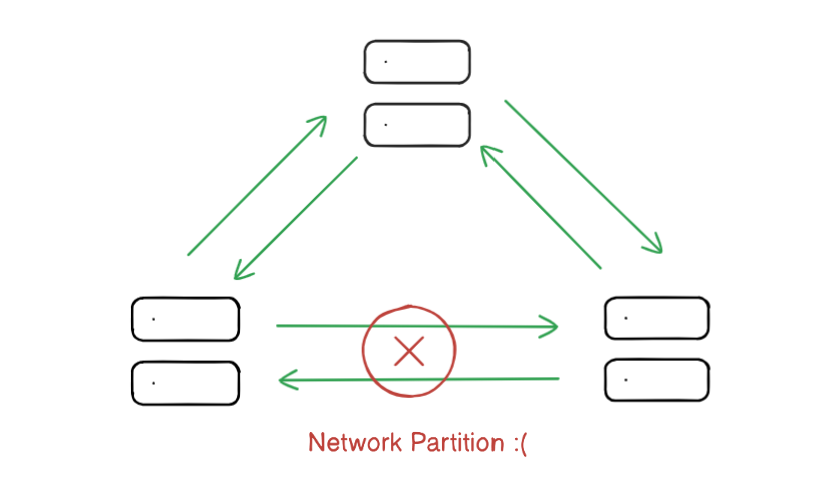
Partition tolerance ensures that the system continues to function even when network partitions occur. This means the system can handle lost or delayed messages and still maintain its overall integrity. In a distributed system, being partition-tolerant is essential for building robust and resilient applications that can withstand network failures and keep operating smoothly.
CAP Theorem Trade-offs
As we discussed, the real essence of the CAP Theorem is that it's challenging for a distributed system to achieve Consistency, Availability, and Partition Tolerance simultaneously at their highest levels. Consequently, system designers must prioritize two of these characteristics, inevitably compromising on the third. This results in three primary trade-offs: CP, CA, and AP systems.
However, be cautious of oversimplifying these compromises. In practice, the trade-offs are more nuanced, and system designers often make dynamic adjustments based on specific needs and circumstances.
CP Systems: Consistency & Partition Tolerance
In systems where Consistency and Partition Tolerance are prioritized (CP systems), the goal is to ensure that all nodes in the network maintain a consistent view of the data, even during network disruptions. This means that when a value is written to one node, it will be updated in all other nodes.
However, CP systems may sacrifice Availability, meaning some data might not be accessible during a network partition. For example, if a network partition occurs, the system might refuse to process read/write requests to maintain consistency, which could lead to some downtime.
CA Systems: Consistency & Availability
CA systems prioritize Consistency and Availability, ensuring that under normal operating conditions, every request to a functioning node returns a successful or failed response with consistent data. This setup provides a constant view of the data and high availability when there are no network issues.
However, CA systems struggle with network partitions. During such events, they may become less available or perform poorly, as they can't maintain their consistency guarantees when nodes are unable to communicate.
Since network failure is unavoidable, a distributed system must tolerate network partition. Thus, a CA system cannot exist in real world applications.
AP Systems: Availability & Partition Tolerance
AP systems prioritize Availability and Partition Tolerance over strong consistency. These systems aim to process queries and provide the most recent available data, even if it may not be completely up-to-date due to network partitioning. Temporary discrepancies in data versions among different nodes are acceptable, with the primary goal being to ensure high availability.
In AP systems, even if some nodes are unreachable due to a partition, the system continues to operate and serve requests. This approach is particularly useful in scenarios where continuous uptime is critical, and eventual consistency is an acceptable trade-off.
Real-world Applications & Examples
Understanding the CAP theorem's application in real-world scenarios is crucial for making informed decisions when designing distributed systems. Here are some practical examples:
Amazon DynamoDB
Amazon DynamoDB, a database service by AWS, prioritizes high Availability and Partition Tolerance (AP). Initially offering only eventual consistency, it now provides a strong consistency option. This means that when you request the latest data through a consistent read, DynamoDB returns a highly up-to-date response. It effectively handles network partitions, maintaining high availability and offering both consistency types to meet various needs.
MongoDB
MongoDB is a popular Database Management System (DBMS) often used for running real-time applications across different locations. MongoDB follows the CP trade-off, prioritizing Consistency and Partition Tolerance over Availability. This makes it suitable for applications where data accuracy is critical, even if it means sacrificing some availability during network partitions.
Apache Cassandra
Apache Cassandra is an open-source, distributed NoSQL database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra allows clients to specify the number of servers that a write must go to before it's considered committed, offering flexibility between AP and CA models. Writes to a single server are more "AP," while writes to quorum or all servers lean towards "CA."
Conclusion
I hope this discussion on CAP theorem has made the complexities and trade-offs of designing distributed systems a bit clearer, or at least a bit less confusing.
If you have any doubts or suggestions, feel free to ping me on LinkedIn. Your engagement is greatly appreciated. Happy coding :)